
Part 2: Measuring LLM Inference Performance: Metrics, Tradeoffs, and Optimization Strategies
From TTFT to Throughput: Understanding the speed vs. accuracy balance in large language model deployments

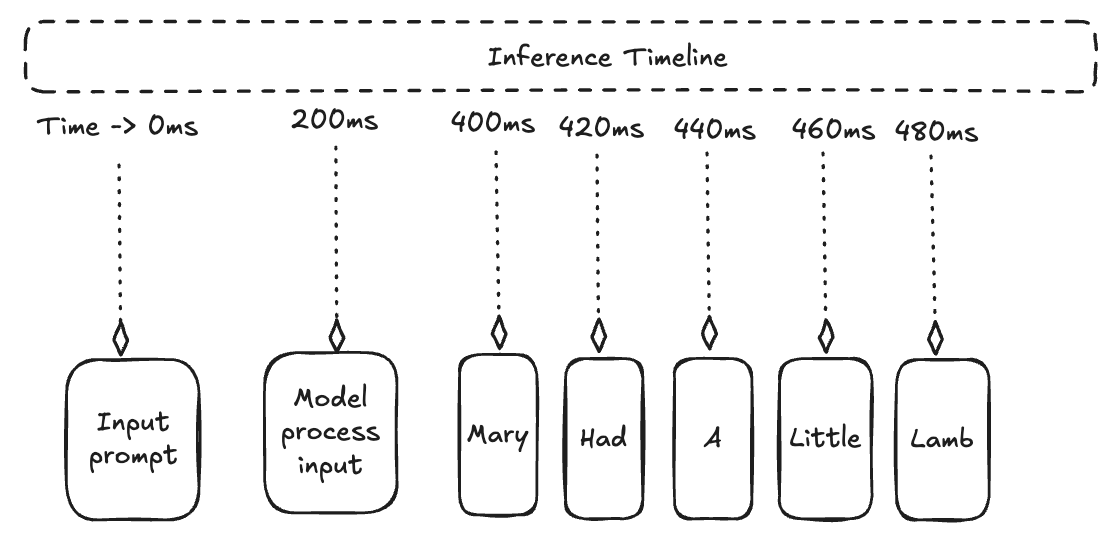
Measuring the inference performance of large language models (LLMs) is crucial to understanding how effectively they respond to input prompts and produce outputs in real-world applications. In this second part of our blog, we will explore key metrics used to measure LLM inference performance and discuss the tradeoffs between speed and accuracy.
Key Metrics for Measuring LLM Inference
TTFT (Time to First Token)
This measures the latency from sending an input prompt to receiving the very first generated token. A lower TTFT indicates faster model responsiveness, which is critical for user experience in interactive applications.
The more tokens or data you send to a model, the longer it takes to process and respond. TTFT tends to increase with the length of the input prompt, as models must "prefill" their internal state before outputting the first token.
TBT (Time Between Tokens)
The duration between generating consecutive tokens. Consistent and low TBT values mean the model can sustain a smooth and continuous output stream.
TPOT (Time Per Output Token)
The average time taken to produce each output token throughout the generation process. TPOT includes both model computation time and any overheads in the pipeline.
ITL (Inter Token Latency)
Similar to TBT, it captures the latency between each token's generation but often emphasizes variances during output, highlighting any stalls or inefficiencies in token production.
Total Token Throughput
The number of tokens generated per second, representing the overall speed and efficiency of the inference process. Higher throughput indicates better scalability for processing large numbers of requests or generating long outputs.
Tradeoffs Between Speed and Accuracy
Balancing Latency and Quality
Faster inference (low TTFT and TBT) is desirable for responsiveness but can sometimes come at the expense of output quality or accuracy. For example, aggressive optimizations or precision reductions (such as using FP8 instead of FP16) can speed up token generation but may introduce minor degradation in model fidelity.Model Size and Complexity
Larger, more accurate models inherently require more computation, increasing TTFT and token latencies. Deploying smaller or quantized models can improve speed but might reduce the nuance and correctness of generated text.Batching and Parallelism
Processing multiple requests simultaneously can increase throughput but may introduce higher individual latencies due to queuing, affecting responsiveness for single requests.Hardware and Architecture Influence
Advanced hardware like AMD’s MI300X or NVIDIA’s H100 accelerator architectures play a crucial role in mitigating speed-accuracy tradeoffs by enabling high precision computations at low latency with massive parallelism and memory bandwidth. Efficient interconnects and caching help reduce ITL and maximize throughput without sacrificing accuracy.
Conclusion
Effective measurement of LLM inference performance requires examining a combination of latency and throughput metrics—TTFT, TBT, TPOT, ITL, and token throughput—to fully capture speed and responsiveness. Understanding and managing the tradeoffs between speed and accuracy allows developers to tailor inference deployments to their specific application needs, be it real-time chatbots needing low latency or batch generation tasks favoring maximum accuracy and throughput.
This balanced approach, combined with cutting-edge accelerator technologies, will continue to push the boundaries of scalable, efficient, and high-quality LLM deployment in diverse AI workloads.
References: